목차
참고 자료 : https://learn.microsoft.com/ko-kr/azure/databricks/dev-tools/sdk-python
Python용 Databricks SDK - Azure Databricks
Python용 Databricks SDK를 사용하여 Python을 사용하여 Databricks 작업을 자동화하는 방법을 알아봅니다.
learn.microsoft.com
로컬 개발 컴퓨터에서 Python용 Databricks SDK를 시작하는 방법을 설명한다.
참고 자료 : https://github.com/databricks/databricks-sdk-py
GitHub - databricks/databricks-sdk-py: Databricks SDK for Python (Beta)
Databricks SDK for Python (Beta). Contribute to databricks/databricks-sdk-py development by creating an account on GitHub.
github.com
sdk를 사용하는 예제를 모아둔 github
1. 환경 구축 및 설치
- Pycharm Professional
python 3.13.7과 Pycharm만 설치된 상태
python.exe -m pip install --upgrade pippip install jupyter notebook
- databricks-sdk 설치
pip install databricks-sdk
pip show databricks-sdk
- databricks-cli 설치
pip install databricks-cli- 구성 파일 설정
물론 cli를 설치하지 않고 하드 코딩의 형식도 가능하지만
from databricks.sdk import WorkspaceClient
w = WorkspaceClient(
host = 'https://...',
token = '...'
)
# 하드 코딩 형식보안상의 이슈가 있을 수 있으므로, 구성파일을 만드는 것을 권장한다.
https://learn.microsoft.com/ko-kr/azure/databricks/dev-tools/auth/config-profiles
Azure Databricks 구성 프로필 - Azure Databricks
Azure Databricks 구성 프로필을 사용하고 설정하는 방법 알아보기
learn.microsoft.com
설정하는 법 :
2025.09.08 - [Data Engineering/Databricks] - [Databricks] cli
[Databricks] cli
관련 문서 : https://docs.databricks.com/aws/en/dev-tools/cli/ What is the Databricks CLI? | Databricks on AWSLearn about the Databricks CLI, a command-line interface utility that enables you to work with Databricks.docs.databricks.com 1. 환경 구축w
radaonmommy.tistory.com
- 구성 파일 확인
cd ~
DIR
cat .\.databrickscfg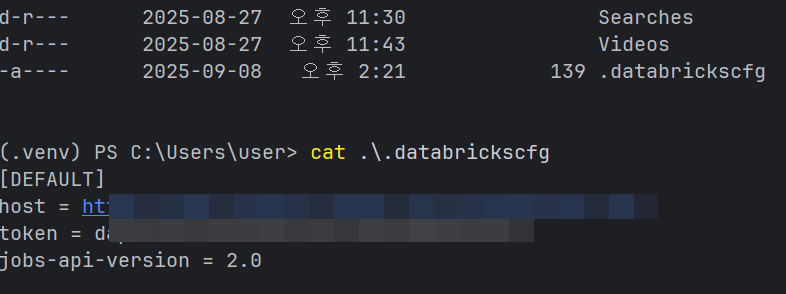
2. databricks-sdk 사용하기
a. Databricks의 기본 인증과정
| 인증 매개 | 설명 | |
| 1 | 환경변수 | DATABRICKS_HOST 및 DATABRICKS_TOKEN와 같은 환경 변수를 확인 |
| 2 | 구성 파일 | 사용자의 홈 디렉터리에 있는 .databrickscfg 파일을 확인하고, 기본 프로필(DEFAULT)의 정보를 사용 |
| 3 | 사용자 지정 프로필 | DATABRICKS_CONFIG_PROFILE 환경 변수가 설정되어 있다면, 해당 이름의 프로필을 .databrickscfg 파일에서 찾아 사용 |
.databrickscfg 파일을 이미 만들었고 그 안에 유효한 인증 정보가 있다면,
DATABRICKS_CONFIG_PROFILE 같은 환경 변수를 따로 설정하지 않아도 CLI/SDK가 자동으로 해당 파일을 읽어 인증을 완료한다.
b. 클러스터 리스트 확인하기
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
for c in w.clusters.list():
print(c.cluster_name)
c. 볼륨 파일 리스트 확인하기.
volumes_path = '/Volumes/training/jhm/artifact'
d = w.dbutils.fs.ls(volumes_path)
for f in d:
print(f.path)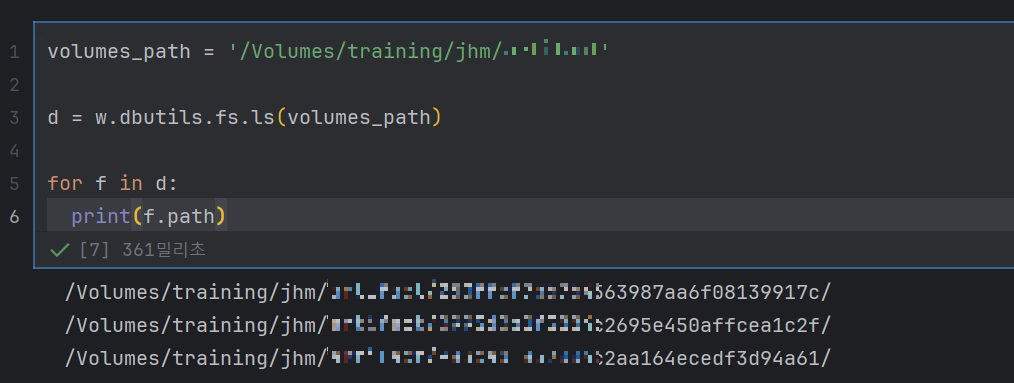
d. job 실행하기
job_id_to_run = 1234567890 # 실행할 Job의 ID
run = w.jobs.run_now(job_id=job_id_to_run)
print(f"Job run started with ID: {run.run_id}")
e. job 상태 확인하기
job_run_status = w.jobs.get_run(run_id=run.run_id)
print(f"Current state: {job_run_status.state.life_cycle_state}")Current state: RunLifeCycleState.RUNNING
| life_cycle_state | 설명 |
| PENDING | 실행 대기중 |
| RUNNING | 실행중 |
| TERMINATED | 실행 완료 |
| SKIPPED | 실행 건너 뜀 |
| INTERNAL_ERROR | 내부 오류로 인한 실패 |
f. 카탈로그 테이블 확인
from databricks.sdk import WorkspaceClient
# WorkspaceClient 객체 생성
w = WorkspaceClient()
# 테이블을 조회할 카탈로그와 스키마 이름 지정
catalog_name = "your_catalog_name"
schema_name = "your_schema_name"
# w.tables.list() : 테이블 이름 목록
tables = w.tables.list(catalog_name=catalog_name, schema_name=schema_name)
for table in tables:
print(table.full_name)
g. 테이블 상세 조회
table_name = "<catalog_name>.<schema_name>.<table_name>"
table_info = w.tables.get(full_name=table_name) # full_name은 필수 파라미터
print(f"테이블 이름: {table_info.name}")
print(f"카탈로그: {table_info.catalog_name}")
print(f"스키마: {table_info.schema_name}")
print(f"테이블 타입: {table_info.table_type}")
print(f"생성 시간: {table_info.created_at}")
print(f"소유자: {table_info.owner}")
columns = table_info.columns
for col in columns:
print(f"컬럼 이름: {col.name}")
h. 트러블 슈팅
Error: unable to parse response. This is likely a bug in the Databricks SDK for Python or the underlying REST API해당 문구가 발생하면 대부분의 이유가 인증 구성일 수 있다.
1. Databricks 호스트가 올바르게 설정되었는지 확인한다.
2. 인증 방법에 수행하려는 API 작업에 필요한 권한이 있는지 확인한다.
3. 회사 방화벽 뒤에 있는 경우 API 트래픽을 차단하거나 리디렉션하지 않는지 확인한다.
e. databricks-sdk 사용 문서
https://databricks-sdk-py.readthedocs.io/en/latest/
'Data Engineering > Databricks' 카테고리의 다른 글
| [databricks] secrets 파헤치기 (1) | 2025.09.15 |
|---|---|
| [Databricks] cli (0) | 2025.09.08 |
| [Databricks] databricks 내 dataframe 조작 (0) | 2025.09.03 |
| [Databricks] DBeaver 연결 하기 (1) | 2025.09.02 |
| [databricks] Watermark (0) | 2025.06.11 |