Slowly Changing Dimensions (SCD)
- Slowly Changing Dimension의 약자이다.
- 시간 흐름에 따라 차원 테이블이 변경되는 것을 관리하는 전략
- 데이터 웨어하우스 및 레이크하우스 설계에서 필수이다.
SCD 유형별 정리
| 유형 | 설명 | 데이터 예시 | 과거 이력 |
|---|---|---|---|
| Type 0 | 변경 불가 (정적 테이블 전용) | 국가 코드, 통화 등 | 유지 안함 |
| Type 1 | 덮어쓰기 (기존 값 덮어씀) | 이메일 변경 등 | 유지 안함 |
| Type 2 | 이력 보존 (새 레코드 추가) | 주소 변경, 가격 추적 등 | 유지함 |
SCD Type 1 예시
변경 전:
| Product ID | Product Name | Price |
|---|---|---|
| 1 | Product A | 10 |
| 2 | Product B | 20 |
| 3 | Product C | 30 |
변경 후:
| Product ID | Product Name | Price |
|---|---|---|
| 1 | Product A | 50 |
| 2 | Product B | 20 |
| 3 | Product C | 70 |
➡ 기존 데이터를 새 값으로 덮어씀 (과거 이력 보존 안함)
SCD Type 2 구현 시 필요한 열
start_date: 유효 시작 날짜end_date: 유효 종료 날짜 (NULL이면 현재)is_current: 현재 유효 여부 (true/false)
📘 SCD Type 2 예시
변경 전:
| Product ID | Product Name | Price | Current | Effective Date | End Date |
|---|---|---|---|---|---|
| 1 | Product A | 10 | True | 2023-01-01 | NULL |
| 2 | Product B | 20 | True | 2023-01-01 | NULL |
| 3 | Product C | 30 | True | 2023-01-01 | NULL |
변경 후:
| Product ID | Product Name | Price | Current | Effective Date | End Date |
|---|---|---|---|---|---|
| 1 | Product A | 10 | False | 2023-01-01 | 2023-01-03 |
| 2 | Product B | 20 | True | 2023-01-01 | NULL |
| 3 | Product C | 30 | False | 2023-01-01 | 2023-01-03 |
| 1 | Product A | 50 | True | 2023-01-03 | NULL |
| 3 | Product C | 70 | True | 2023-01-03 | NULL |
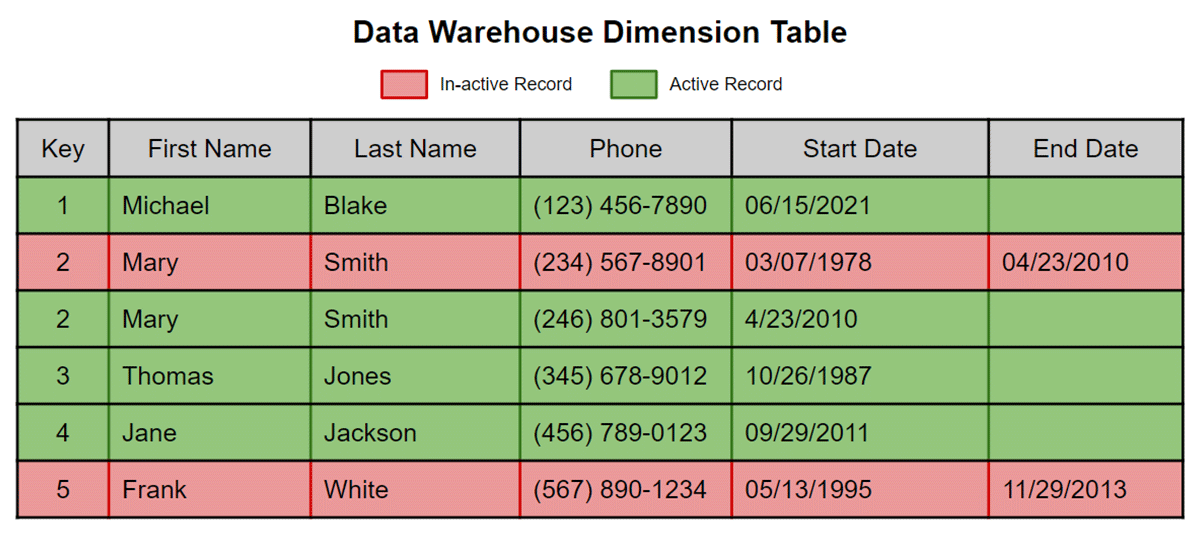
➡ 새 값이 들어올 경우, 기존 레코드는 is_current = False 로 변경되고 새로운 레코드가 추가된다.
또는 이미지를 통해 볼 수 있듯이 end Date의 존재여부로 현재값이 유효한 값인지도 판단 할 수 있다.
Type 2 구현 시에는 MERGE 쿼리나 Delta Lake의 조건부 삽입/업데이트를 활용해야 한다.
def type2_upsert(microBatchDF, batch):
microBatchDF.createOrReplaceTempView("updates")
sql_query = """
MERGE INTO books_silver
USING (
SELECT updates.book_id as merge_key, updates.* FROM updates
UNION ALL
SELECT NULL as merge_key, updates.*
FROM updates
JOIN books_silver ON updates.book_id = books_silver.book_id
WHERE books_silver.current = true AND updates.price <> books_silver.price
) staged_updates
ON books_silver.book_id = merge_key
WHEN MATCHED AND books_silver.current = true AND books_silver.price <> staged_updates.price THEN
UPDATE SET current = false, end_date = staged_updates.updated
WHEN NOT MATCHED THEN
INSERT (book_id, title, author, price, current, effective_date, end_date)
VALUES (staged_updates.book_id, staged_updates.title, staged_updates.author, staged_updates.price, true, staged_updates.updated, NULL)
"""
spark.sql(sql_query)해당 함수는 마이크로 배치때마다 임시 뷰를 만들고 실행부를 정의한다.
쿼리 설명:
사용자 지정 병합 키를 기반으로 마이크로 배치 업데이트를 books_silver 테이블에 병합하고 있음.
동일한 book_id지만 가격이 변경된 경우 current = false로 업데이트하고 end_date를 설정.
변경된 데이터는 새 레코드로 INSERT (current = true, effective_date 설정).
즉, 가격 변동 이력 전체를 추적함.
%sql
CREATE TABLE IF NOT EXISTS books_silver
(book_id STRING, title STRING, author STRING,
price DOUBLE, current BOOLEAN, effective_date TIMESTAMP, end_date TIMESTAMP)해당하는 테이블이 존재하는지 확인하고 없다면 만들기.
def process_books():
schema = "book_id STRING, title STRING, author STRING, price DOUBLE, updated TIMESTAMP"
query = (spark.readStream
.table("bronze")
.filter("topic = 'books'")
.select(F.from_json(F.col("value").cast("string"), schema).alias("v"))
.select("v.*")
.writeStream
.foreachBatch(type2_upsert)
.option("checkpointLocation", "dbfs:/mnt/demo_pro/checkpoints/books_silver")
.trigger(availableNow=True)
.start()
)
query.awaitTermination()
process_books()bronze 테이블에서 books 토픽 데이터가 스트리밍으로 들어오면, 구조화된 후 가격 변경 여부에 따라 books_silver 테이블에 SCD Type 2 방식으로 기록됨.
변경 이력 전체가 유지되며, 최신 데이터만 current = true 상태로 존재함.
비교: SDC Type2 vs Delta Time Travel
장기적인 버전 관리 솔루션을 제공하기에는 비용과 지연 시간 측면에서 Delta time travel이 확장성이 떨어진다.
VACUUM 커멘드를 사용하면 테이블 기록 버전이 삭제되는 점도 있다.
참고 자료
Loading a Data Warehouse Slowly Changing Dimension Type 2 Using Matillion on Databricks Lakehouse Platform
Learn more about modern, low-code approaches to ETL and how the combination of Databricks and the Matillion visual ELT platform make it easy to integrate data from any source into a Databricks SQL warehouse.
www.databricks.com
'Data Engineering > Databricks' 카테고리의 다른 글
| [databricks] 테이블 복사(CTAS , Shallow Clone, Deep Clone) (1) | 2025.06.09 |
|---|---|
| [databricks]Change Data Capture(CDC), Change Data Feed(CDF) (1) | 2025.06.05 |
| [databricks] Delta Table 제약 조건 추가 및 위반처리 (1) | 2025.06.05 |
| [databricks] Struct Streaming Deduplication (1) | 2025.06.05 |
| [databricks] Singleplex , Multiplex (0) | 2025.06.05 |